
De nos jours, l'intelligence artificielle, basée sur la Apprentissage par renforcementLe problème de l'apprentissage par renforcement, appelé apprentissage renforcé, se heurte à un certain nombre de difficultés qui ne permettent pas son application dans des scénarios réels. Pour comprendre ce problème, il faut comprendre le fonctionnement de l'apprentissage renforcé, connu sous le nom de Apprentissage par renforcement.
L'apprentissage par renforcement est nécessaire pour que l'intelligence artificielle puisse apprendre par elle-même. Il fonctionne en fixant des objectifs à une machine afin qu'elle puisse prendre des décisions aléatoires. Certaines de ces décisions se rapprochent de l'objectif fixé, tandis que d'autres s'en éloignent. C'est par les récompenses données pour les décisions proches de l'objectif que la machine apprend.
La réalité est qu'à ce jour, l'intelligence artificielle n'a été appliquée que pour résoudre une seule tâche à la fois. Cela rend impossible l'application de l'IA au monde réel. Dans le même temps, le monde réel repose sur des scénarios instables, non stationnaires et des données changeantes. Ajouté à la nécessité de résoudre des tâches et sous-tâches en permanence, nous avons jugé nécessaire de remédier à cette inefficacité.
La technologie d'IA de substrat a apporté la solution. Pour commencer, notre architecture parvient à organiser les tâches en objectifs et sous-objectifs d'une manière qui permet aux agents de Substrate AI de résoudre des tâches qui ont des sous-tâches implicites. En soi, il s'agit déjà d'une révolution qui est en passe d'être brevetée.
En termes d'application dans le monde réel, la technologie Substrate AI peut être utilisée dans des cas où la technologie standard ne suffit pas. Notre technologie, dont le brevet est en cours d'homologation, possède des caractéristiques qui lui permettent de s'auto-adapter aux nouveaux changements de l'environnement sans devoir recycler les agents d'IA. Cela permet au processus de se poursuivre dans des environnements changeants.
Il convient de noter que notre technologie suit un modèle émotionnel inspiré de la biologie et basé sur les neurosciences et la psychologie. Notre technologie a la capacité d'expérimenter, d'une certaine manière, des états d'esprit qui permettent de prendre certaines décisions ou d'autres. Grâce aux récompenses, certaines décisions sont plus populaires que d'autres, orientant la stratégie dans la bonne direction avec moins de risques. Ainsi, les émotions peuvent guider la stratégie et la sélection, en décomposant la prise de décision en plusieurs étapes.
Les acteurs sont ainsi dotés d'une capacité émotionnelle à rendre plus rationnelle la des décisions, en rapprochant les deux mondes : celui du système limbique (la partie du cerveau chargée des fonctions les plus primitives et immédiates) et celui des fonctions du lobe frontal (la partie plus "rationnelle" ou "humaine" du cerveau).
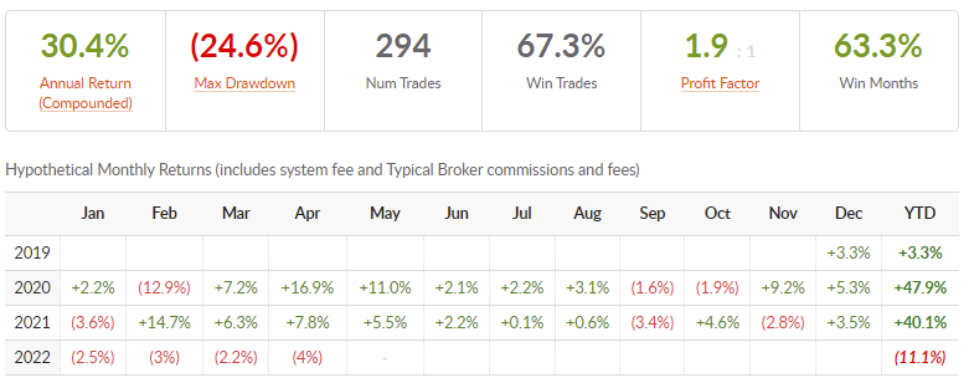
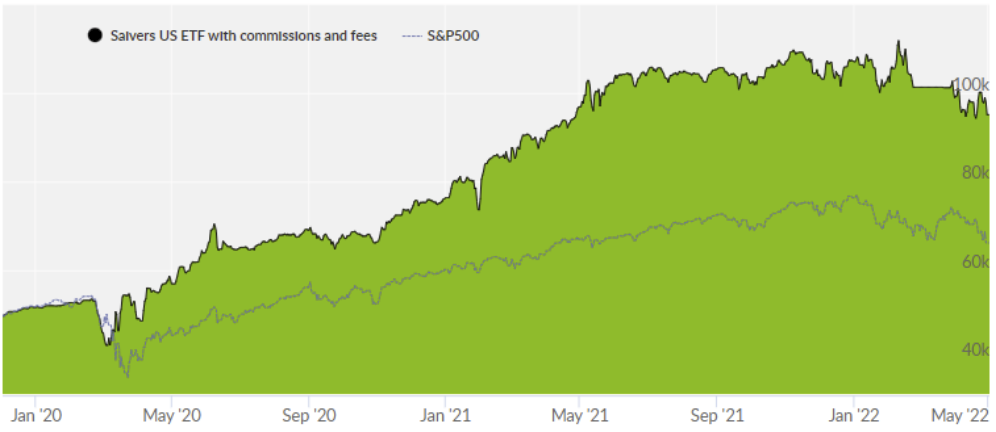
* Graphique de la plateforme d'outils collectifs qui valide la technologie. De janvier 2020 à aujourd'hui, il a surperformé le rendement du S&P500 (indice américain standard).
Alors que les algorithmes de l Apprentissage par renforcement ont réussi à résoudre des problèmes complexes dans une variété d'environnements simulés, leur adoption dans le monde réel a été lente. Voici quelques-uns des défis qui ont entravé leur adoption et la façon dont nous les relevons :
- Les agents chargés de l'apprentissage par renforcement doivent avoir une grande expérience.
Les méthodes d'apprentissage par renforcement génèrent de manière autonome des données d'apprentissage en interagissant avec l'environnement. Par conséquent, le taux de collecte des données est limité par la dynamique de l'environnement. Les environnements à forte latence ralentissent la courbe d'apprentissage. En outre, dans les environnements complexes comportant des espaces à haute dimension, une exploration approfondie est nécessaire avant de trouver une bonne solution.
De grandes quantités de données sont nécessaires. Dans notre cas, nous préformons les agents et les données sont utilisées plus efficacement, de sorte que nous n'avons pas besoin d'une telle quantité d'informations.
- Récompenses à terme échu
L'agent d'apprentissage peut échanger des récompenses à court terme contre des gains à long terme. Si ce principe fondamental rend l'apprentissage par renforcement utile, il rend également difficile pour l'agent de découvrir la politique optimale. Cela est particulièrement vrai dans les environnements où le résultat est inconnu jusqu'à ce qu'un grand nombre d'actions séquentielles soient prises. Dans ce scénario, il est difficile d'attribuer le mérite du résultat final à une action antérieure et cela peut introduire une grande variation pendant la formation. Le jeu d'échecs est un exemple pertinent à cet égard, car l'issue de la partie est inconnue tant que les deux joueurs n'ont pas joué tous leurs coups.
Notre agent utilise l'apprentissage hiérarchique, ce qui, en combinaison avec d'autres éléments, signifie que nous pouvons générer de manière récursive une structure du monde. Grâce à cette structure, nous pouvons faire une abstraction de haut niveau qui n'est pas disponible pour de nombreux agents. Cela signifie qu'il ne peut pas recevoir de récompenses à long terme, mais seulement des besoins immédiats.
- Manque d'interprétabilité
Une fois qu'un agent d'apprentissage par renforcement a appris la politique optimale et qu'il est déployé dans l'environnement, il prend des mesures en fonction de son expérience. Pour un observateur extérieur, la raison de ces actions peut ne pas être évidente. Ce manque d'interprétabilité interfère avec le développement de la confiance entre l'agent et l'observateur. Si un observateur pouvait expliquer les actions réalisées par l'agent d'apprentissage par renforcement, cela l'aiderait à mieux comprendre le problème et à découvrir les limites du modèle, notamment dans les environnements à haut risque.
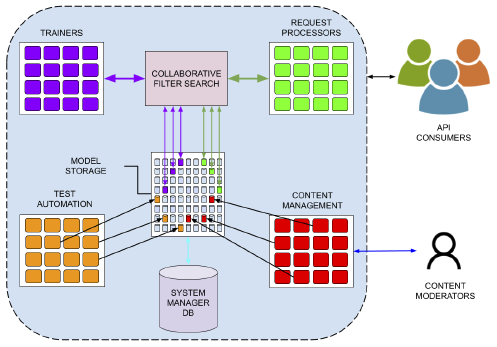
Nous travaillons actuellement sur la partie recherche, enfin comme nous l'appelons, l'agent distribué. D'une part, notre technologie peut améliorer l'efficacité énergétique car elle utilise des modèles beaucoup plus petits et peut être distribuée aux appareils selon les besoins. Du côté de la boîte noire, lorsque les gens interagissent avec le système, celui-ci peut fournir un retour d'information.
Nous vous laissons avec une pilule dans laquelle nos experts expliquent le processus de Apprentissage par renforcement:
Source : Substrat AI