
A día de hoy, la Inteligencia Artificial, basada en el Reinforcement Learning, se encuentra con diversas dificultades que no permiten su aplicación en escenarios reales. Con el fin de comprender este problema, debemos entender el funcionamiento del aprendizaje reforzado, conocido como Reinforcement Learning.
El aprendizaje reforzado es necesario para que la Inteligencia Artificial pueda aprender por sí misma. Funciona marcando objetivos a una máquina para que ésta pueda tomar decisiones de forma aleatoria. Algunas de estas decisiones se acercan al objetivo marcado, mientras otras, se alejan. Es a través de recompensas dadas a la toma de decisiones cercanas al objetivo que la máquina aprende.
La realidad es que hasta la fecha, la Inteligencia Artificial no ha podido aplicarse más que para resolver una única tarea al mismo tiempo. Esto imposibilita la aplicación de la IA al mundo real. A su vez, contamos con que el mundo real se sostiene sobre escenarios inestables, no estacionarios y con datos cambiantes. Añadido a la necesidad de la resolución de tareas y subtareas de manera contínua, nos hemos visto en la necesidad de resolver esta ineficiencia.
La tecnología de Substrate AI ha dado con la solución. Para comenzar, nuestra arquitectura logra organizar las tareas en objetivos y subobjetivos de una manera que permite a los agentes de Substrate AI resolver tareas que tienen subtareas implícitas. Esto en sí mismo ya es una revolución que está en proceso de patentamiento.
Respecto a la aplicación en el mundo real, la tecnología de Substrate AI se puede usar en casos donde la tecnología estándar no alcanza. Nuestra tecnología, pendiente de patente, tiene características que permiten que su tecnología se auto-adapte a los nuevos cambios en el ambiente sin necesidad de volver a capacitar a los agentes de IA. Esto permite que en entornos cambiantes el proceso continúe.
Cabe destacar que nuestra tecnología sigue un modelo emocional al inspirarse en la biología tomando como base la neurociencia y la psicología. Nuestra tecnología tiene la capacidad de experimentar, de una manera determinada, estados de ánimo que hacen que se tomen unas decisiones u otras. A través de las recompensas, unas decisiones son mas populares que otras, encaminando la estrategia a la dirección correcta implicando menos riesgos. Por lo que las emociones pueden guiar la estrategia y la selección desglosando así la toma de decisiones en múltiples pasos.
Los agentes están así dotados de una capacidad emocional para hacer más racional las decisiones, acercando ambos mundos: el del sistema límbico (la parte del cerebro a cargo de las funciones más primitivas e inmediatas) y la de las funciones del lóbulo frontal (la parte más «racional» o «humana» del cerebro).
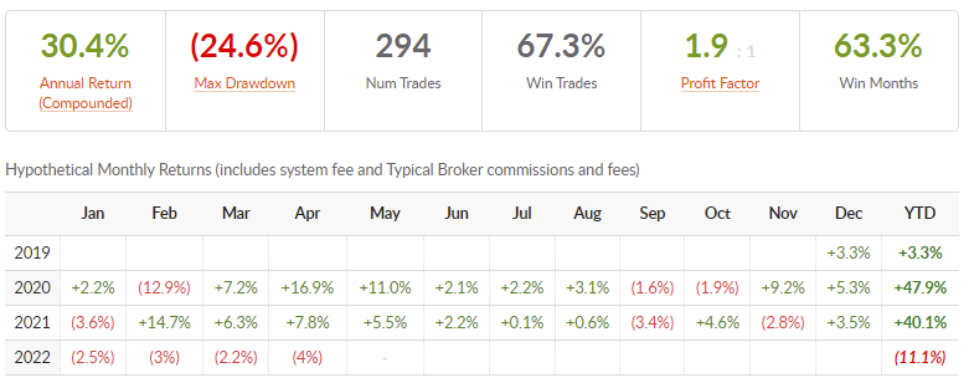
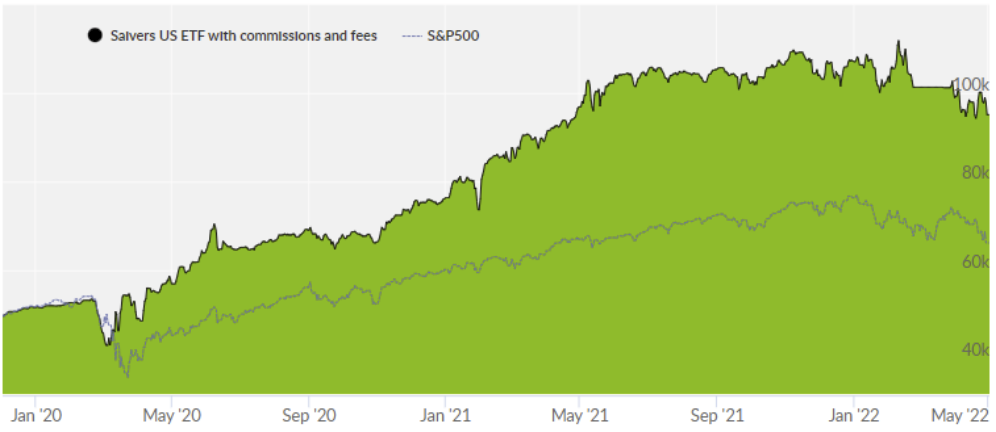
* Gráfico de la plataforma Collective tools que valida la tecnología. Desde enero de 2020 hasta hoy, ha superado el retorno del S&P500 (standard índice americano).
Si bien los algoritmos del Reinforcement Learning han tenido éxito en la resolución de problemas complejos en diversos entornos simulados, su adopción en el mundo real ha sido lenta. Aquí están algunos de los desafíos que han dificultado su aceptación y cómo los resolvemos:
- Los agentes del Reinforcement Learning necesitan amplia experiencia.
Los métodos de Reinforcement Learning generan de forma autónoma datos de entrenamiento interactuando con el medio ambiente. Por lo tanto, la colección de tasa de datos está limitada por la dinámica del ambiente. Los entornos con alta latencia ralentizan la curva de aprendizaje. Además, en complejos entornos con espacios de alta dimensión, se necesita una amplia exploración antes de encontrar una buena solución.
Son necesarios grandes cantidades de datos. En nuestro caso pre-entrenamos a los agentes y se utilizan los datos de forma más eficiente, por lo que no necesitamos tal cantidad de información.
- Recompensas atrasadas
El agente de aprendizaje puede compensar recompensas a corto plazo por ganancias a largo plazo. Mientras este principio fundamental hace que el Reinforcement Learning sea útil, también lo hace difícil para que el agente descubra la póliza óptima. Esto es especialmente cierto en entornos donde el resultado es desconocido hasta que se toma un gran número de acciones secuenciales. En este escenario, asignar el crédito a una acción previa por el resultado final es desafiante y puede introducir una gran variación durante la capacitación. El juego de ajedrez es un ejemplo relevante aquí, donde el resultado del juego es desconocido hasta que ambos de los jugadores han hecho todos sus movimientos.
Nuestro agente utiliza un aprendizaje por jerarquía, que en combinación con otros elementos, hace que de forma recursiva podamos generar una estructura del mundo. Gracias a dicha estructura, podemos hacer una abstracción a alto nivel que no está disponible para muchos agentes. Esto hace que no pueda recibir recompensas largoplacistas sino de una necesidad inmediata.
- Falta de interpretabilidad
Una vez que un agente de Reinforcement Learning ha aprendido la política óptima y se despliega en el ambiente, toma acciones basadas en su experiencia. Para un observador externo, la razón de estas acciones podrían no ser obvias. Esta falta de interpretabilidad interfiere con el desarrollo de la confianza entre el agente y el observador. Si un observador pudiera explicar las acciones que realiza el agente de Reinforcement Learning, le ayudaría a comprender mejor el problema y descubrir las limitaciones del modelo, especialmente en los entornos de alto riesgo.
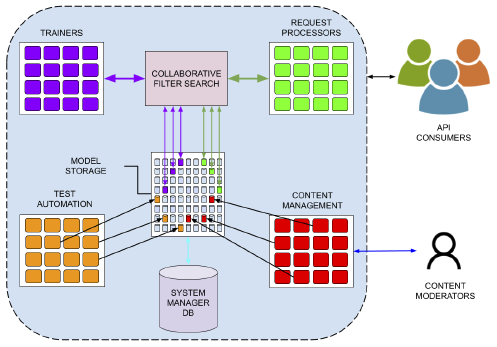
Actualmente trabajamos en la parte de investigación, bien como llamamos, el agente distribuido. Por un lado, nuestra tecnología puede mejorar la eficiencia energética porque utiliza modelos mucho más pequeños y se puede distribuir en dispositivos en función de su necesidad. En cuanto a la caja negra, conforme la gente interactúa con el sistema, pudiendo así facilitar feedback.
Os dejamos una píldora en la que nuestros expertos explican el proceso de Reinforcement Learning:
Fuente: Substrate AI