
Today, AI technology is advancing rapidly, but Is it really as smart as we think? Today we explore a simple logical question that has stumped cutting-edge AI models such as ChatGPT, Claude 3 Opus, Gemini and Llama. Find out how these AI giants are dealing with the problem of "Alice in Wonderland".an easy question for humans but puzzling for machines.
Is AI Really Intelligent?
The rapid advances in AI have led many to fear that machines can replace human jobs. But is AI really as intelligent as it seems?
Alice's Dilemma Test
In a recent test, researchers from the nonprofit AI research organization LAION posed a logical question to various AI modelsincluding all versions of ChatGPT, Anthropic's Claude 3 Opus, Google's Gemini, and Meta's Llama, as well as Mistral AI's Mextral, Mosaic's Dbrx, and Cohere's Command R+. The question, known as the "Alice in Wonderland problem," is as follows:
Alice has 2 brothers and 1 sister. How many sisters does Alice's brother have?
Although the question requires some thought, it is not an impossible riddle. The correct answer is that Alice's brother has 2 sisters: Alice and her other sister.
In the following video, the CTO of Substrate AI, explains this Alice in Wonderland problem better.
AI Failures and Limitations
Despite the simplicity of the question, most of the AI models provided incorrect answers. They failed to recognize Alice as one of the sisters. This error, easily avoidable by a human, highlights a significant deficiency in the AI's logical reasoning skills.
When the researchers analyzed the responses of the AI models, they found that only the latest OpenAI model, GPT-4, achieved a success rate that could be considered technically satisfactory by academic standards. However, the other models failed.
Why does AI fail?
The researchers inquired into the reasons why these AI models could not correctly answer such a simple question.. When the models were asked to explain their reasoning, they produced bizarre and erroneous lines of thought. Even more puzzling, when corrected, the models often reaffirmed their incorrect answers with greater confidence, offering nonsensical justifications to back up their faulty logic.
The Solution: Serenity Star
This general pattern indicates a clear break in the reasoning capabilities of state-of-the-art AI models. Furthermore, the models' overconfidence in their incorrect answers, coupled with plausible explanations, underscores a significant area for improvement in AI development. Given these observations, it is clear that AI has a long way to go. Current models are not as intelligent as they appear to be and often rely on faulty reasoning to justify their errors.
However, we have tested Artificial Intelligence agents from Serenity Star may have the same problem and we found that we could learn how to solve this problem in a general way. To do this Serenity* uses its multi-step reasoning, long-term memory and knowledge graphs with code generation to solve this problem.
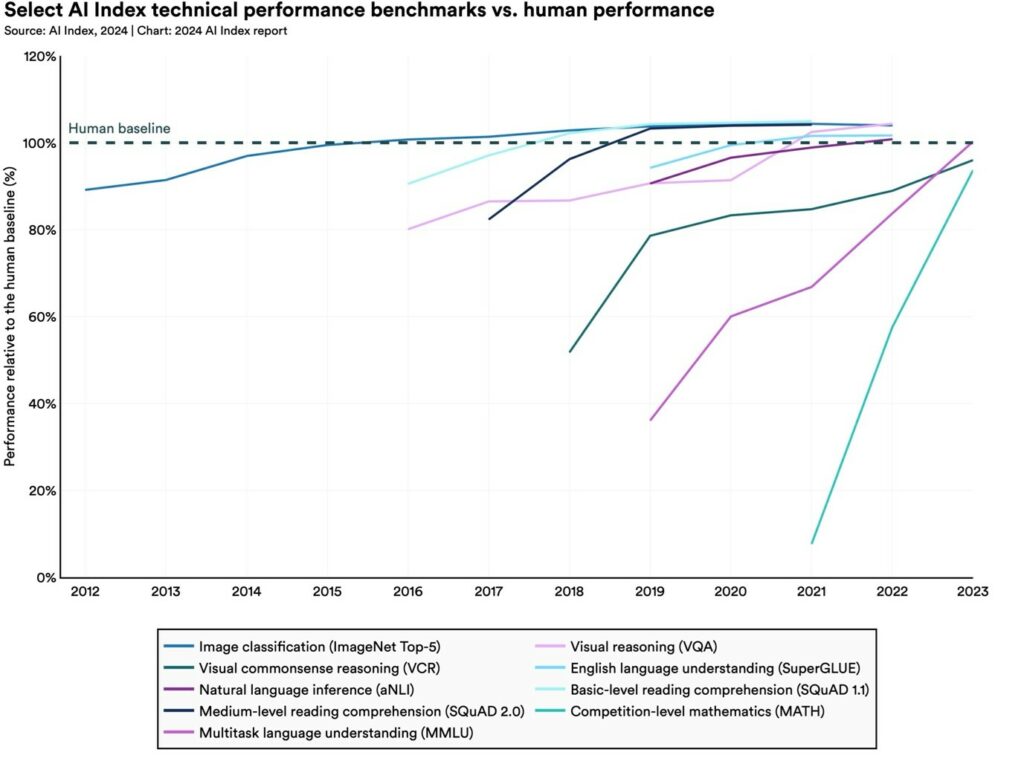
It is also worth noting that AI has surpassed human capabilities in other areas, such as image classification, visual reasoning, and English comprehension, according to the AI Index Report 2024.
Conclusion: The Future of Artificial Intelligence
The advances in AI are impressive, but this article highlights that there is still much room for improvement. As we continue to develop and refine AI technologies, understanding and addressing these limitations will be crucial.