
Nowadays, Artificial Intelligence, based on the Reinforcement LearningThe problem of reinforcement learning, known as reinforced learning, encounters several difficulties that do not allow its application in real scenarios. In order to understand this problem, we must understand the functioning of reinforced learning, known as Reinforcement Learning.
Reinforcement learning is necessary for Artificial Intelligence to learn on its own. It works by setting goals for a machine so that it can make random decisions. Some of these decisions move closer to the goal set, while others move away from it. It is through rewards given for making decisions close to the target that the machine learns.
The reality is that to date, Artificial Intelligence has only been applied to solve a single task at a time. This makes it impossible to apply AI to the real world. In turn, the real world relies on unstable, non-stationary scenarios and changing data. Added to the need to solve tasks and subtasks on a continuous basis, we have found it necessary to solve this inefficiency.
Substrate AI technology has come up with the solution. To begin with, our architecture manages to organize tasks into goals and subgoals in a way that allows Substrate AI agents to solve tasks that have implicit subtasks. This in itself is already a revolution that is in the process of being patented.
Regarding real-world application, Substrate AI technology can be used in cases where standard technology falls short. Our patent-pending technology has features that allow its technology to self-adapt to new changes in the environment without the need to retrain AI agents. This allows the process to continue in changing environments.
It should be noted that our technology follows an emotional model inspired by biology and based on neuroscience and psychology. Our technology has the ability to experience, in a certain way, moods that make some decisions or others. Through rewards, some decisions are more popular than others, steering the strategy in the right direction involving less risk. So emotions can guide strategy and selection, thus breaking down decision making into multiple steps.
The agents are thus endowed with an emotional capacity to make more rational the decisions, bringing both worlds closer together: that of the limbic system (the part of the brain in charge of the most primitive and immediate functions) and that of the frontal lobe functions (the more "rational" or "human" part of the brain).
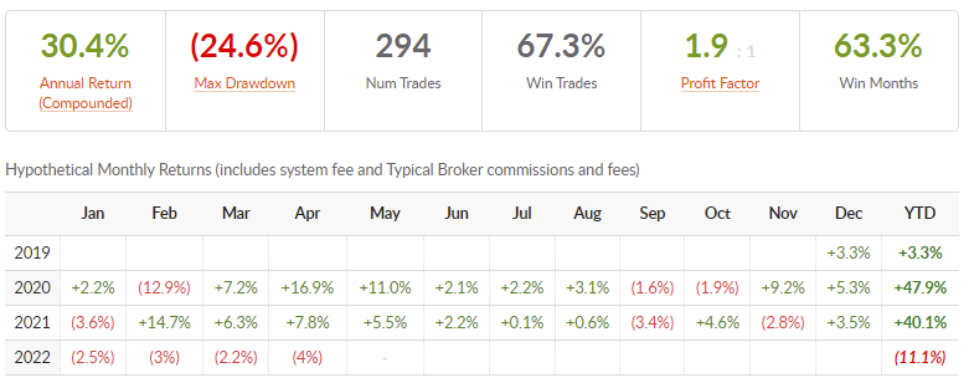
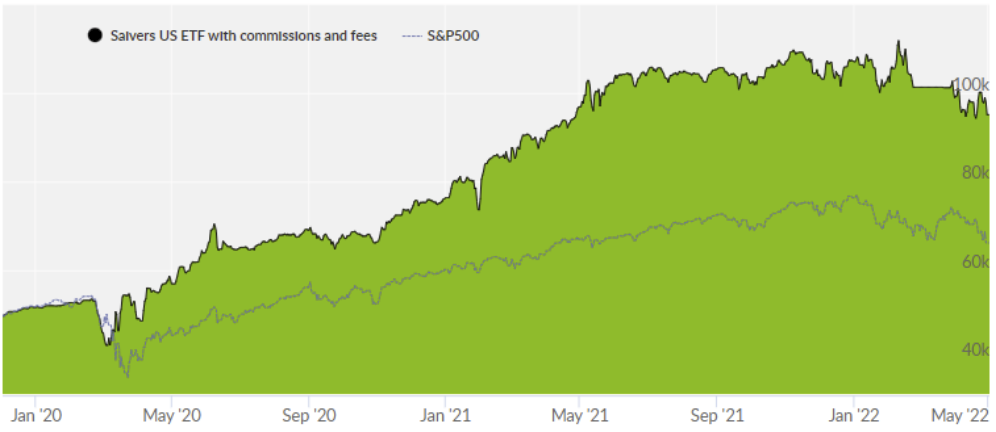
* Chart of the Collective tools platform that validates the technology. From January 2020 to date, it has outperformed the return of the S&P500 (standard American index).
While the algorithms of the Reinforcement Learning have been successful in solving complex problems in a variety of simulated environments, their adoption in the real world has been slow. Here are some of the challenges that have hindered their acceptance and how we solve them:
- Reinforcement Learning agents need extensive experience.
Reinforcement Learning methods autonomously generate training data by interacting with the environment. Therefore, the data rate collection is limited by the dynamics of the environment. High latency environments slow down the learning curve. Moreover, in complex environments with high-dimensional spaces, extensive exploration is needed before finding a good solution.
Large amounts of data are necessary. In our case we pre-train the agents and the data is used more efficiently, so we do not need such a large amount of information.
- Delayed rewards
The learning agent can trade off short-term rewards for long-term gains. While this fundamental principle makes Reinforcement Learning useful, it also makes it difficult for the agent to discover the optimal policy. This is especially true in environments where the outcome is unknown until a large number of sequential actions are taken. In this scenario, assigning credit to a prior action for the final outcome is challenging and can introduce a great deal of variation during training. The game of chess is a relevant example here, where the outcome of the game is unknown until both players have made all their moves.
Our agent uses hierarchy learning, which, in combination with other elements, allows us to recursively generate a structure of the world. Thanks to this structure, we can make a high-level abstraction that is not available to many agents. This means that it cannot receive long-term rewards, but only immediate need.
- Lack of interpretability
Once a Reinforcement Learning agent has learned the optimal policy and is deployed in the environment, it takes actions based on its experience. To an outside observer, the reason for these actions may not be obvious. This lack of interpretability interferes with the development of trust between the agent and the observer. If an observer could explain the actions performed by the Reinforcement Learning agent, it would help him or her better understand the problem and discover the limitations of the model, especially in high-risk environments.
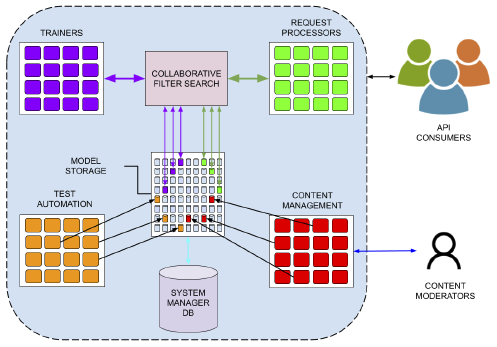
We are currently working on the research part, well as we call it, the distributed agent. On the one hand, our technology can improve energy efficiency because it uses much smaller models and can be distributed to devices as needed. On the black box side, as people interact with the system, we can provide feedback.
We leave you with a pill in which our experts explain the process of Reinforcement Learning:
Source: Substrate AI